Difference between KILL QUERY and KILL CONNECTION in MySQL
Recently we discussed the difference between the MySQL commands KILL QUERY and KILL CONNECTION at work.
The MySQL documentation states the following:
KILL permits an optional CONNECTION or QUERY modifier:
KILL CONNECTION is the same as KILL with no modifier: It terminates the connection associated with the given processlist_id, after terminating any statement the connection is executing.
KILL QUERY terminates the statement the connection is currently executing, but leaves the connection itself intact.
In order to test the behavior manually, you can use two different MySQL connections by starting the client twice.
I had to disable the automatic reconnection which is enabled by the MySQL client per default.
To do so, I simply had to add the following to ~/.my.cnf:
[mysql]
reconnect=false
A small test programm
In order to play around with both commands, I needed SQL statements which take a little while, in order to have enough time to kill them.
While SLEEP() comes to mind, it is not ideal because MySQL detects that sleeping does not change any data.
The following Python program stores large blobs in the MySQL database.
While it is not recommended to store binary data in MySQL because it is slow, it is a good use case for demoing some behavior of the database.
The snipped creates random binary files of 100 MB in a loop and stores them in a table.
It also stores the SHA256 hash of each file, so that we can later ensure that the file has actually been written into the database entirely.
After all, we want to ensure that either way of killing a query does ensure that the transaction itself is atomic, meaning that it either goes through entirely, ro gets rolled back.
The important part is that we wrap the entire loop into a transaction.
import hashlib
import os
import time
import mysql.connector
# Replace these with your own database credentials
db_config = {
'host': '127.0.0.1',
'port': '3306',
'user': 'root',
'database': 'MeasurementDB',
}
try:
# Connect to the MySQL database
conn = mysql.connector.connect(**db_config)
cursor = conn.cursor(dictionary=True)
# Create a table for measurement data
create_table_query = """
CREATE TABLE IF NOT EXISTS DataBlobs (
id INT AUTO_INCREMENT PRIMARY KEY,
file_name VARCHAR(255) NOT NULL,
file_data LONGBLOB NOT NULL,
file_size INT NOT NULL,
file_type VARCHAR(100) NOT NULL,
file_hash char(64) NOT NULL
);
"""
cursor.execute(create_table_query)
cursor.execute("TRUNCATE TABLE DataBlobs")
# Start a transaction
conn.start_transaction()
try:
for x in range(0,10):
# Define the file size in bytes
file_size = 100 * 1024 * 1024
# Generate a random binary file
random_data = os.urandom(file_size)
# Specify the file name
file_name = "random_file.bin"
# Write the random data to the file
with open(file_name, "wb") as file:
file.write(random_data)
file = open(file_name,mode='rb').read()
# Compute SHA256 hash
file_hash = hashlib.sha256(file).hexdigest();
cursor.execute("SELECT CONNECTION_ID() AS conn_id")
query_result = cursor.fetchone()
print("Current Connection ID: {}".format(query_result['conn_id']))
insert_query = "INSERT INTO DataBlobs (file_name, file_data, file_size, file_type, file_hash) VALUES (%s, %s, %s, %s, %s)"
tic = time.time()
cursor.execute(insert_query, ('random_file-{}.bin'.format(x), random_data, len(random_data), 'application/octet-stream', file_hash))
toc = time.time()
print("-- Insert file {} successfully ({} seconds).".format('random_file-{}.bin'.format(x), str(round((toc - tic),2))))
tic = time.time()
cursor.execute("SELECT file_name, IF((sha2(file_data,256)=file_hash),'equal', 'not equal') AS equal FROM MeasurementDB.DataBlobs ORDER BY id DESC LIMIT 1;")
toc = time.time()
query_result = cursor.fetchone()
print("-- Hash of file {} is {} ({} seconds).".format(query_result['file_name'], query_result['equal'], str(round((toc - tic),2))))
conn.commit()
except mysql.connector.Error as err:
conn.rollback() # Rollback the transaction if there's an error
print(f"Error: {err}")
finally:
cursor.close()
conn.close()
except mysql.connector.Error as err:
print(f"Connection error: {err}")
finally:
conn.close()
Results and Screencasts
Below are the three results I tested.
Run through without killing anything
The following screencast shows the MySQL Workbench and the Python script in the command line.
In this example, the script just runs through without interruptions and commits the entire transaction at the end with a COMMIT.
Then you can see that the data is stored in the table and also our script reports identical hashes.
Long running queries go through uninterrupted
This is the standard case. But what happens if we must abort the query?
Killing the entire connection
The second example shows how we kill the entire connection by using the button in MySQL Workbench.
In AWS RDS you would need tob use the CALL mysql.rds_kill stored procedure provided by AWS, see the docs.
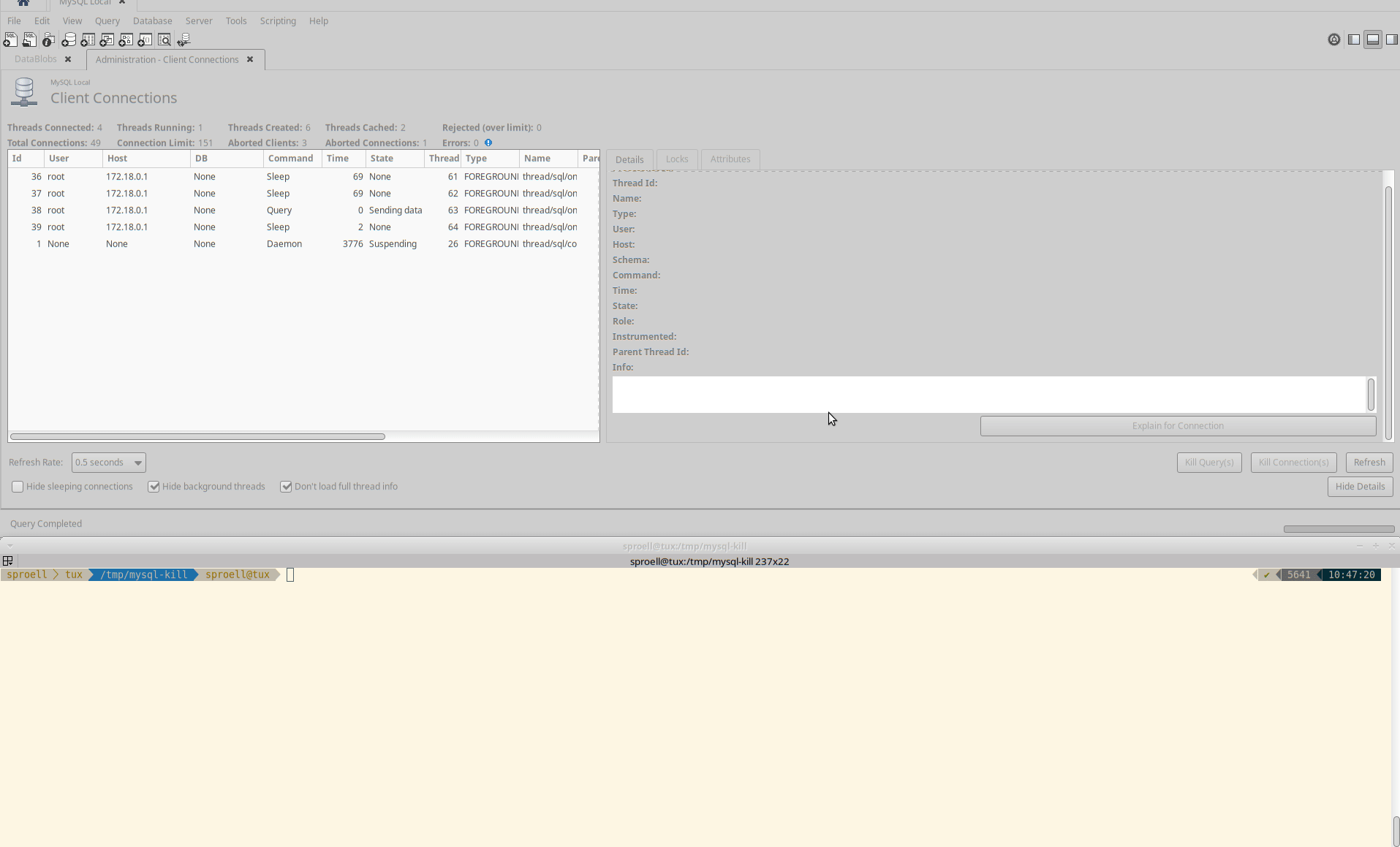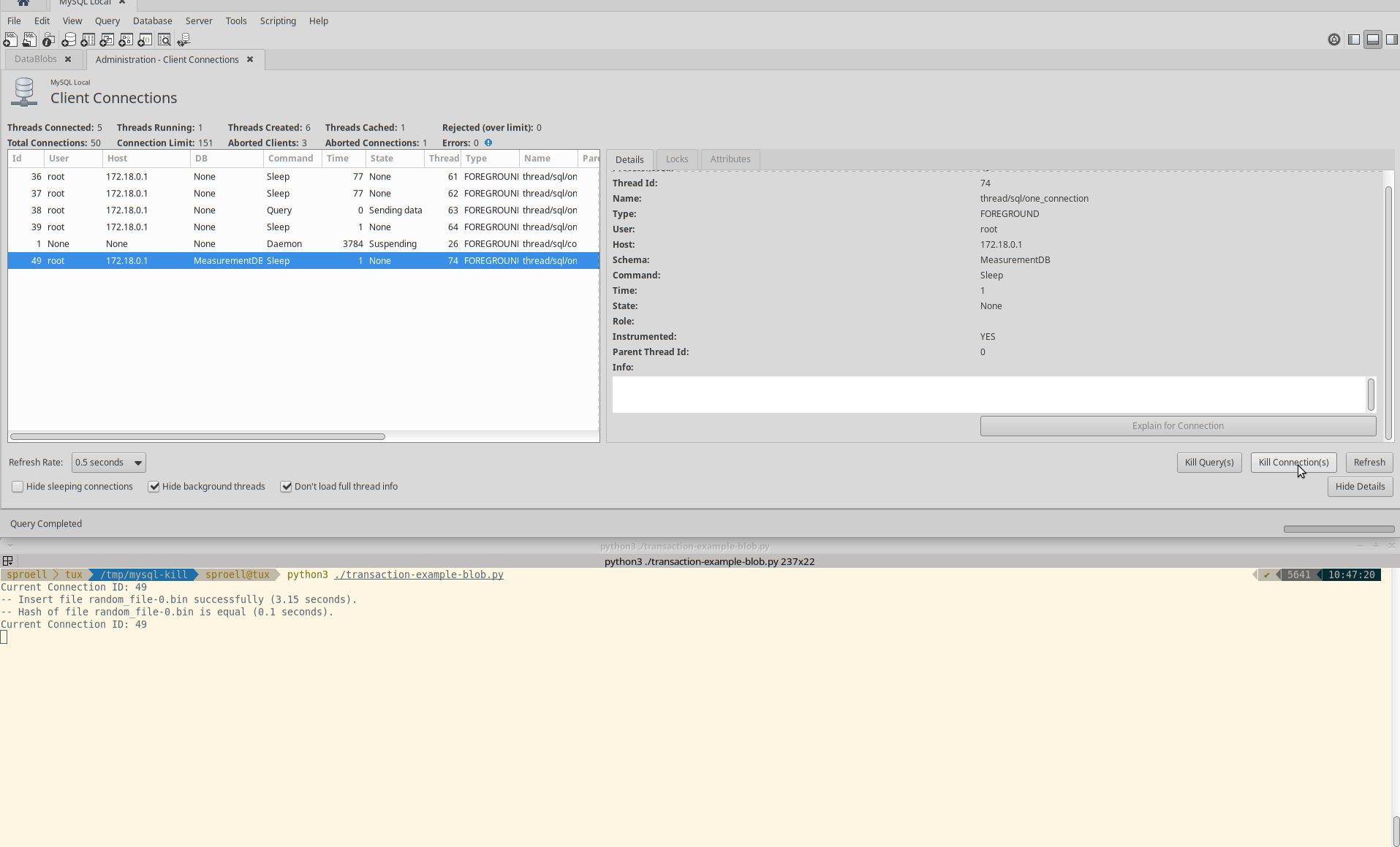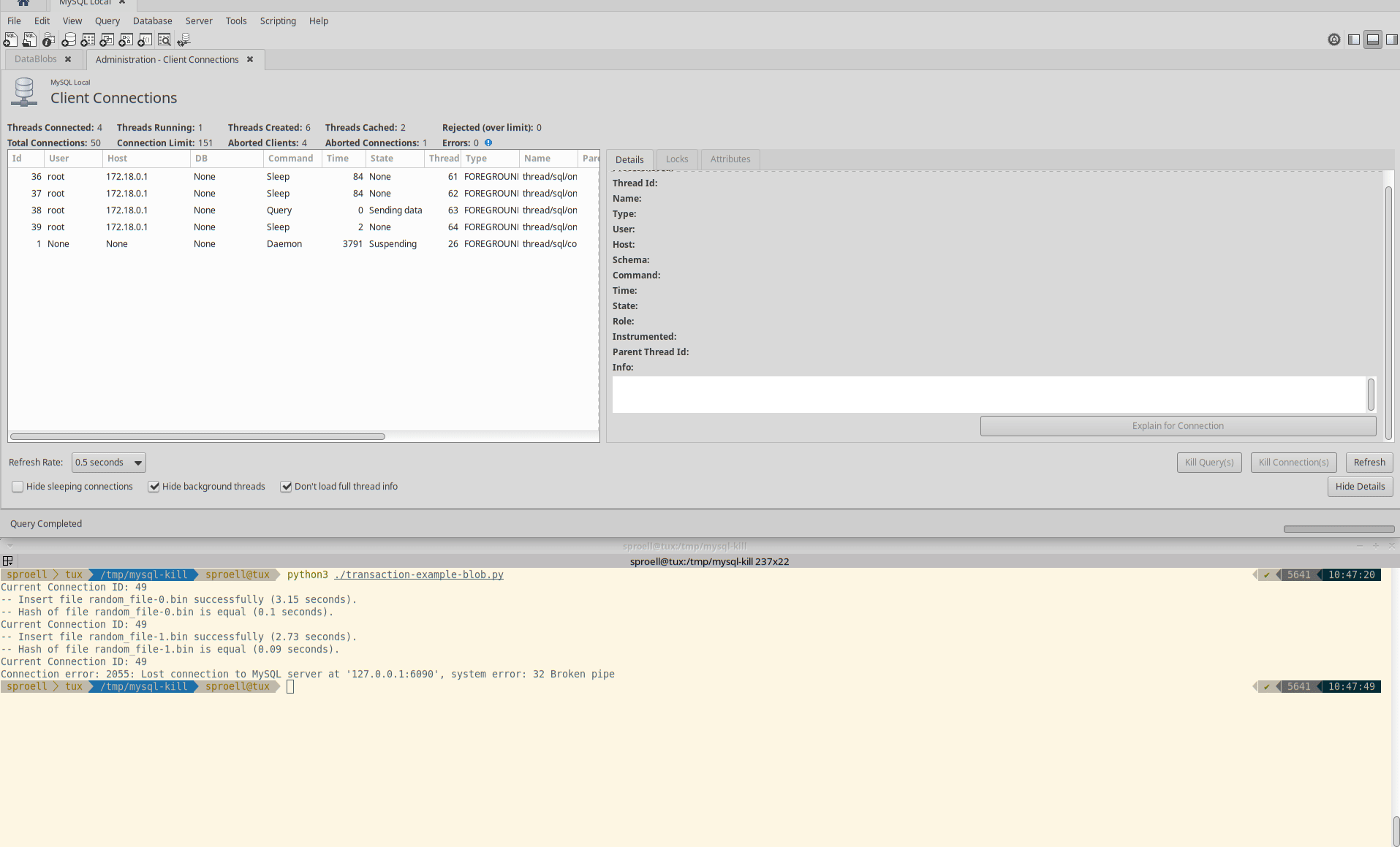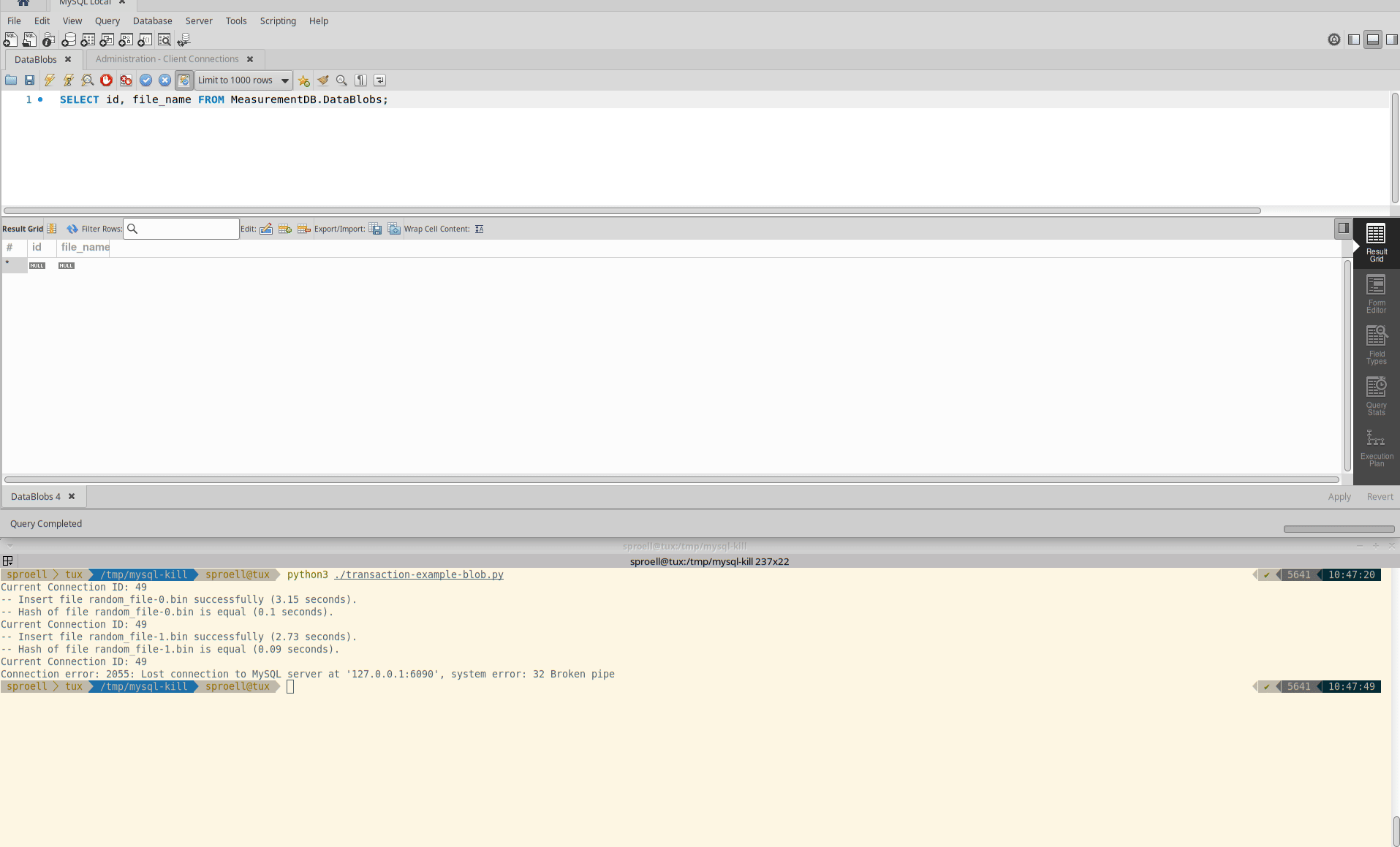
Killing the connection
The entire execution is aborted immediately, the data is rolled back. The MeasurementDB.DataBlobs table remains empty.
Killing only the statement
The third example is interesting, because it seems to depend at which state of the execution of a statement the KILL QUERY arrives.
Instead of killing the entire transaction immediately, it depends if MySQL decides that it rather finishes the current statement.
It might require multiple attempts to actually abort the execution.
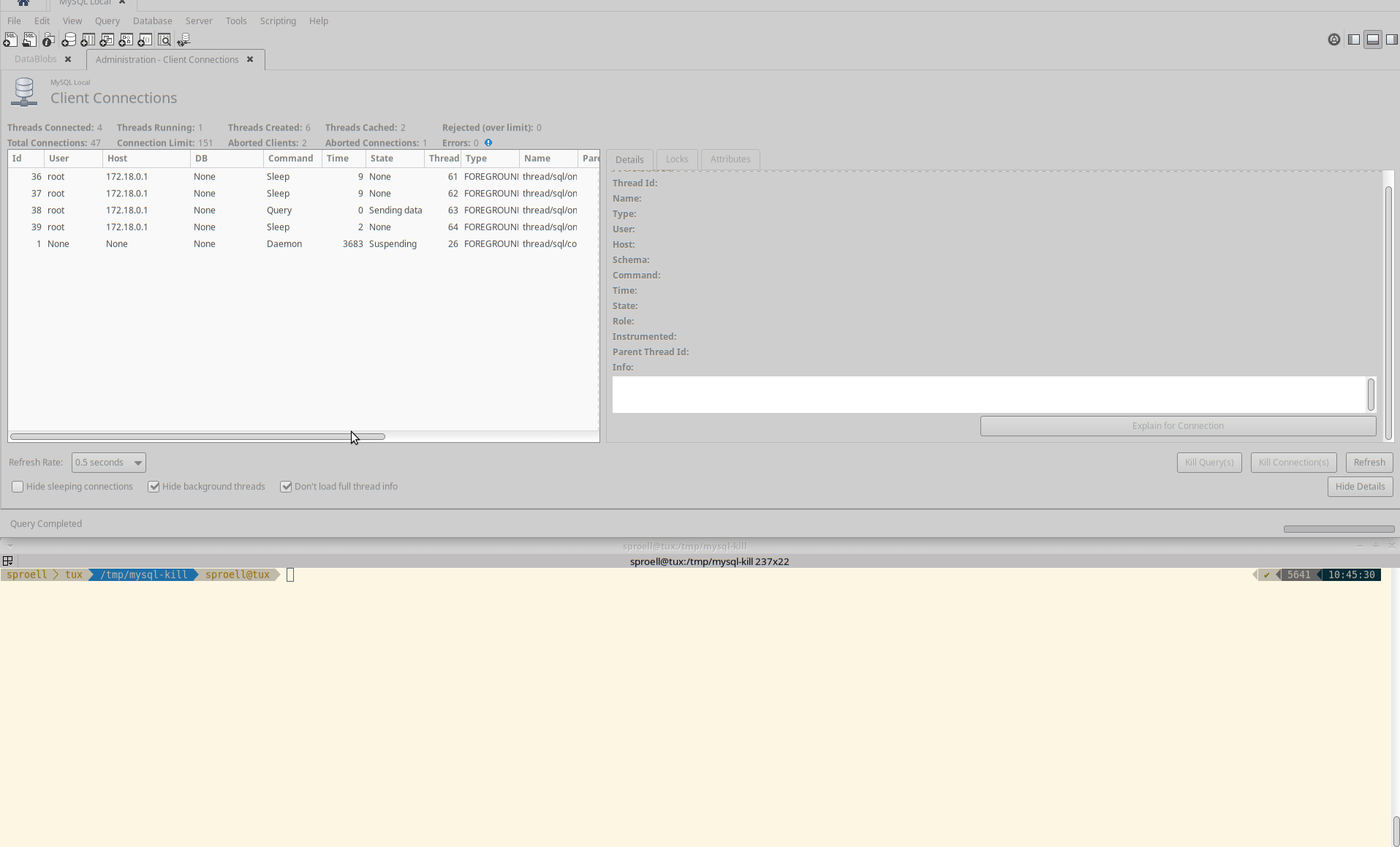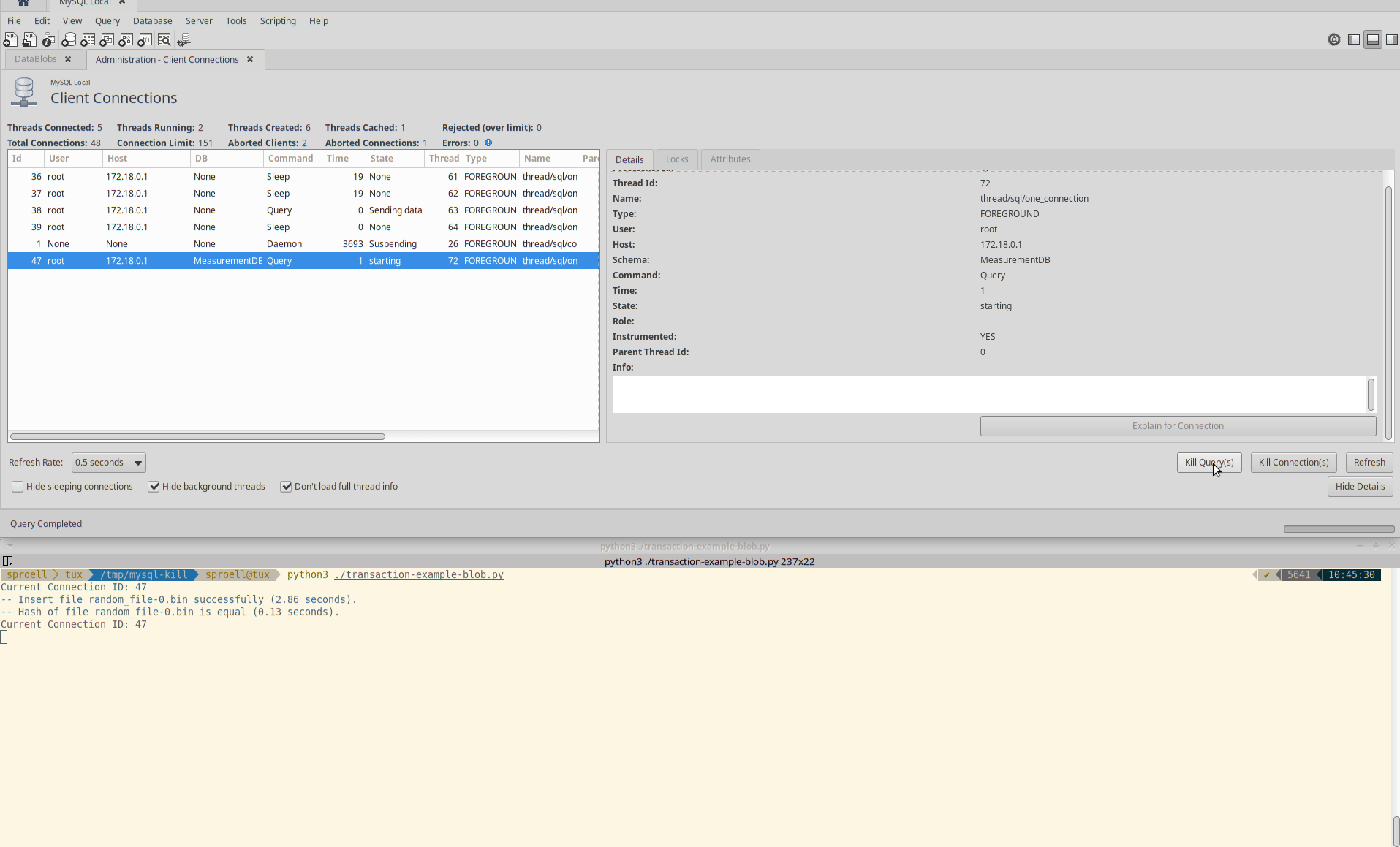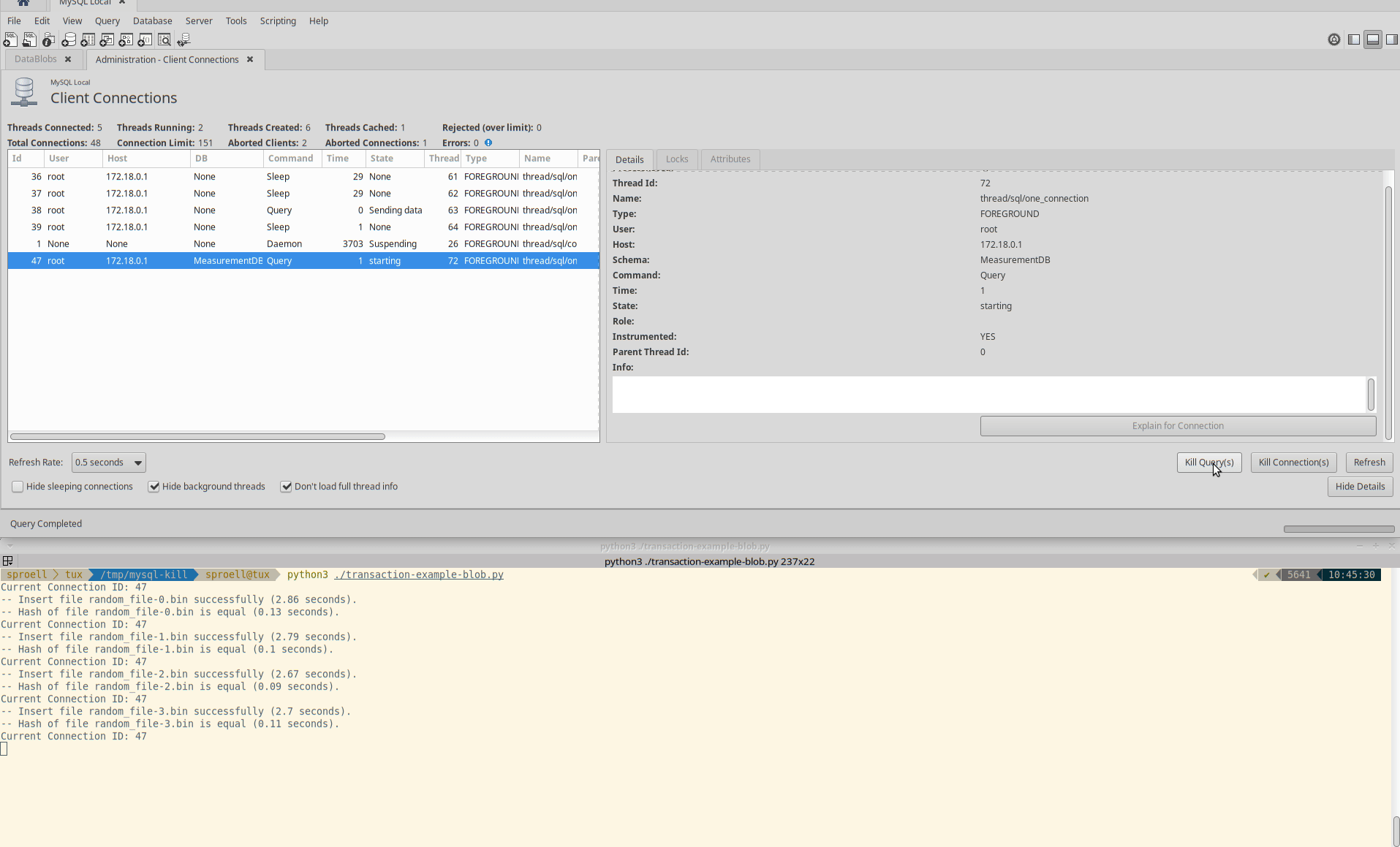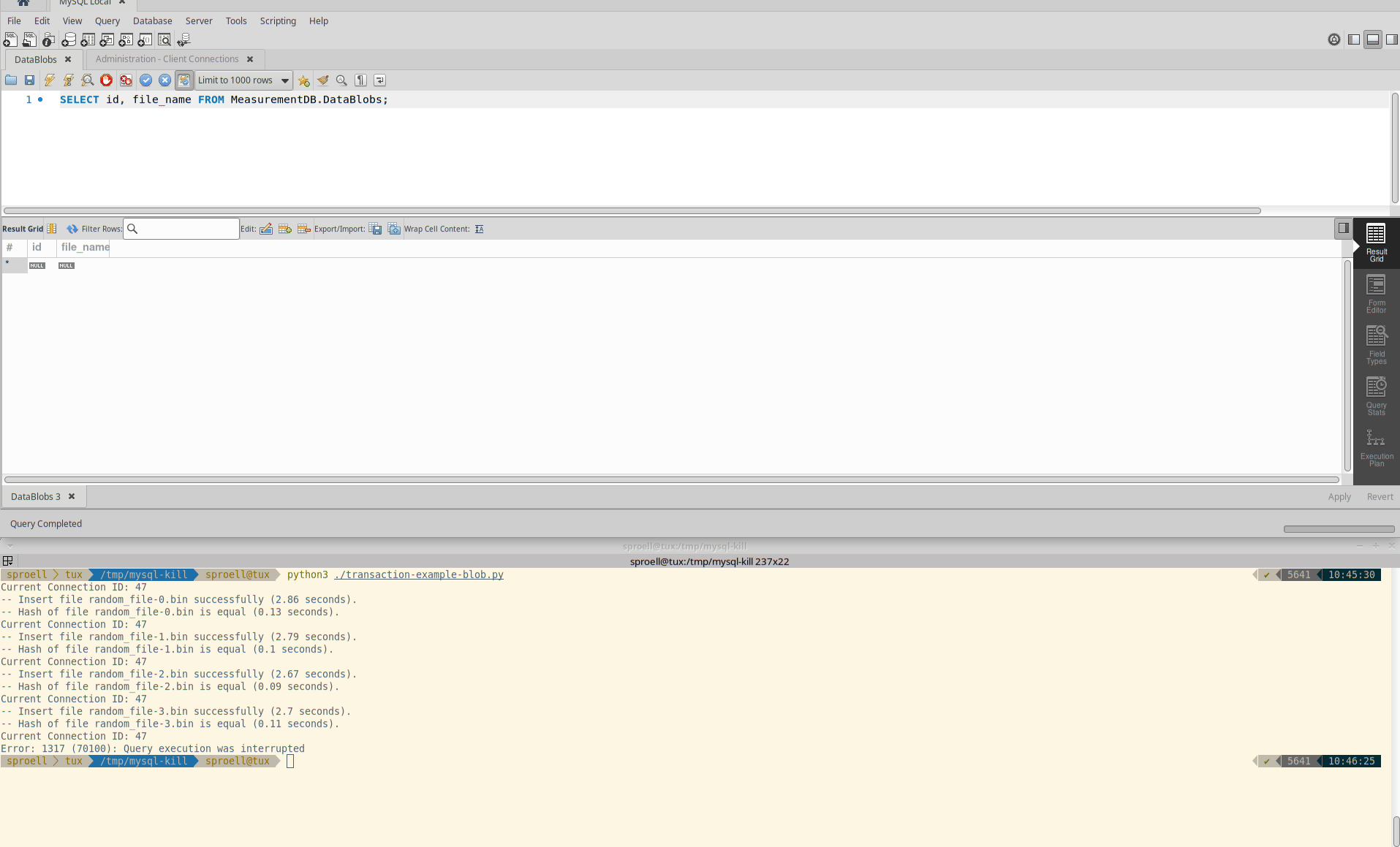
Killing only the query
Also in this case the transaction is rolled back and no data is permanently stored within the table.
